Open Risk Hydra GSOC 2021 Credit Risk Project Wrap Up
The GSOC 2021 collaboration between Open Risk and the Hydra Ecosystem - Project Wrap-Up
Google Summer of Code 2021 came and went amid the still ongoing worldwide pandemic experience. Open Risk was happy to join forces with the Hydra Ecosystem in exploring a proof-of-concept for next generation API’s using Hydra.
The project aimed to guide students (here and here) to build a hypermedia enabled REST service that can serve standardized credit portfolio data. More specifically the project built a REST service as backend for a hypothetical banking entity that collects and disseminates credit portfolio data conforming to an established public standard (the EBA NPL templates) as those are encoded in a Semantic Web based OWL ontology.
Context for the Project
The use of the full specification of the REST architecture (including hypermedia) showcases the advantages of a well-developed REST API (Linked Data) and its potential role in the digitization of banking IT. The use case is, e.g., a bank, a microfinance lender or an asset manager holding a portfolio of loans. One or more databases contain data about borrowers, loans, credit risk assessments, forbearance, collection or enforcement data and other relevant information describing the portfolio. They aim to provide convenient and standards conforming access to allow other parties ( investors, rating agencies, regulators etc.) to gain access to certain facets of the portfolio data, e.g., for due-diligence, valuation or other risk management purposes.
The EBA NPL Templates
Modern API designs are being rapidly adopted in the banking industry across the entire stack, sometimes denoted as the digital transformation of the industry. Standardisation is a significant enabler of this process. In this context European Banking Regulators promote standardisation of a range of data exchanges in particular Non-performing Loan data to remove frictions and risks from the European financial system. A significant related initiative and development concerns the EBA Non-Performing Loan Templates, see also the corresponding EBA Excel sheets and documentation
The NPL Ontology and Standardization of Credit Portfolio Data Exchange using Semantic Web techniques
Building on the regulatory recommendations, the Non-Performing Loan Ontology is a framework that aims to represent and categorize knowledge about non-performing loans using semantic web information technologies. Codenamed NPLO, it codifies the relationship between the various components of a Non-Performing Loan portfolio dataset. You can read more about NPLO here.
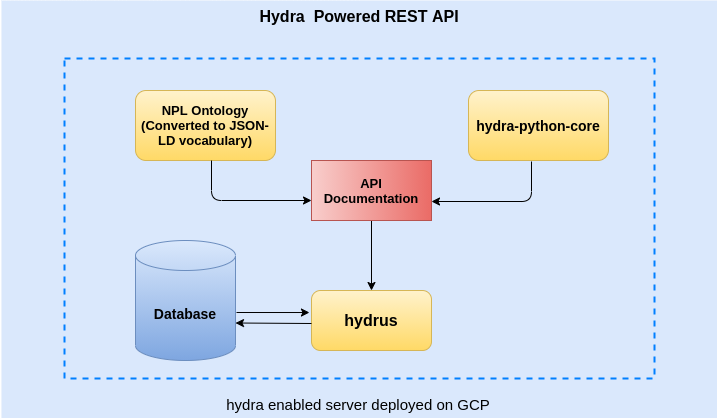
In the context of the GSOC 2021 we explored the possibility of direct generation of API’s using the NPL ontology, the Hydra specification and the Hydrus toolkit that offers a Python based implementation.
The Hydra Ecosystem
What is Hydra? Hydra is a documentation framework that is based on established Linked Data (Semantic Web) tools to build connected Web APIs. A team of developers in the community aims to establish an ecosystem of tools to make Hydra framework operational. The motivation for Hydra from the Hydra project repository states: Building Web APIs seems still more an art than a science. How can we build APIs such that generic clients can easily use them? How do we build those clients? Current APIs heavily rely on out-of-band information such as human-readable documentation and API-specific SDKs. However, this only allows for very simple and brittle clients that are hardcoded against specific APIs. Hydra, in contrast, is a set of technologies that allow to design APIs in a different manner, in a way that enables smarter clients.
The current Hydra specification is available in the Hydra Core Vocabulary and the ecosystem toolkit on which this project was based is available here.
The Project Outcomes
In this evolving and promising backdrop, the GSOC 2021 project used the European Banking Authority Loan Level Templates, as encoded in the Open Risk NPL Ontology, along with the Hydra specification and the previous tools developed by the Hydra Ecosystem as a basis for defining the relevant data domain and delivering a conforming REST API.
The project made significant progress, enhancing both the underlying Hydrus toolkit and demonstrating the functionality using a realistic and fairly complex schema. The very encouraging outcome is that such a complex and realistic schema encoded in OWL can be converted into a functioning API with minimal manual effort.
The GSOC 2021 project results are available in this repository.
Some Interesting Takeaways
One interesting challenge we encountered in implementing the full NPL ontology is its hierarchical structure. Similar to many Object-Oriented Programming paradigms, the OWL ontology supports (and encourages) the use of a hierarchy of classes. A class in OWL is a classification of individuals into groups which share common characteristics.
For example, there is a very general concept of a Borrower, some entity that can borrow funds from another entity ( e.g. a bank). There is a wide variety of possible “borrowers”: From individual persons, to small businesses, to large businesses, to cities / municipalities, countries, or even multi-lateral entities. What data properties do these very different entities share in common? There is deep hierarchy (all of them need to have some unique identifier), different types of businesses share properties that are not needed for individuals and governments etc.
The interesting issue is how one would best work with nested object structures, both in the context of an API that provides access to the data, and in terms of specifying the internal storage schema of the backend database. People familiar with such questions in the context of relational databases might recognize there is not unique or optimal solution but rather various patterns one can follow.
For the purposes of the GSOC 2021 project, given this topic was outside the scope of the original student proposals we opted to adopt a flat ontology (that is, selecting specific subtypes of Counterparties, Loans and Collateral etc so as not to have to implement new hierarchy oriented functionality). It is an interesting task for a future project how one would design ontologies (and/or their interpretation by the toolkit) so that this “flattening” process is not manual but an automated process following some pattern. People interested to learn more about the tools and approaches available can check out the Open Risk Academy course: Class Inheritance in Data Science.