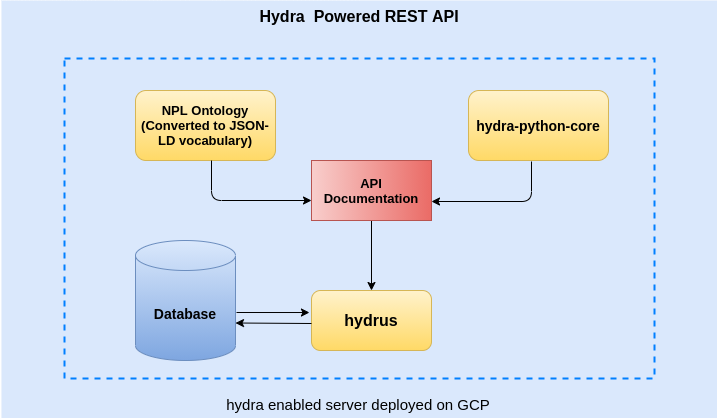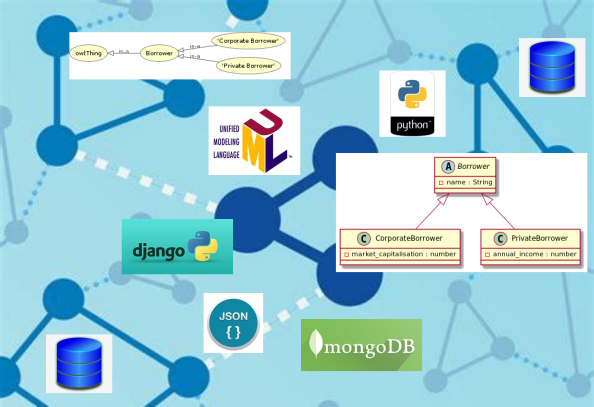
Class Inheritance in Data Science
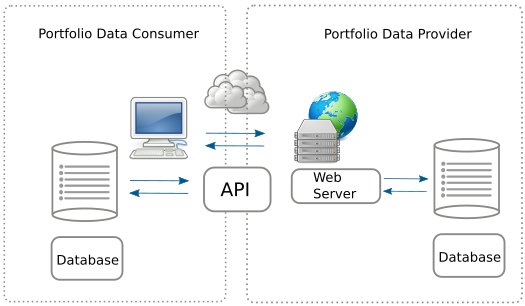
Object-oriented programming and techniques (OOP) such as using classes and inheritance are common in many application programming environments but don't travel well outside computer memory. When considering data science tasks and objectives the transition from object hierarchies to data structures (and vice versa) is not always straightforward. In this short course we explore how some programming languages, data formats, database API's and web frameworks handle hierarchical classes.
Summary
In this short course we explore how some programming languages, data formats, database API’s and web frameworks handle hierarchical classes.
Content
Object-oriented programming and techniques (OOP) such as using classes and inheritance are common in many application programming environments but alas don’t “travel well” outside computer memory. The potentially intricate relationships of objects (both the data they hold and the meaning and possible uses of the data) are not easy to transfer (except of-course by full replication of code and data). Hence when considering data science tasks and objectives that involving exchange of data, the transition from object hierarchies that live inside memory, to data structures that can be exchanged with another computer is not straightforward.