From Big Data, to Linked Data and Linked Models
From Big Data, to Linked Data and Linked Models
The big data problem:
As certainly as the sun will set today, the big data explosion will lead to a big clean-up mess.
How do we know? It is simply a case of history repeating. We only have to study the still smouldering last chapter of banking industry history. Currently banks are portrayed as something akin to the village idiot as far as technology adoption is concerned (and there is certainly a nugget of truth to this). Yet it is also true that banks, in many jurisdictions and across trading styles and business lines, have adopted data driven models already a long time ago. In fact, long enough ago that we have already observed how it call all ended pear shaped, Great Financial Crisis and all.
The tangible evidence of how an industry may struggle to contain its data related liabilities and associated risks goes by the code name BCBS 239.
What is BCBS 239 ? It is a regulatory report that captures regulatory mandated Principles for effective risk data aggregation and reporting that was prompted by the inability of the financial industry to effectively manage data flows linked to important business objectives.
This important precedent exemplifies the other, darker side, of the big data coin. After big data iron (hardware) and the big data software stack is purchased and installed and the big data sets start to flow, commensurately big decisions are to be taken on the basis of said data.
Yet big decisions always carry big risks. Data Quality , Data Provenance (accountability, reproducibility) and other such boring-sounding and poorly understood requirements become suddenly essential to prevent the organization from turning the expected big data based bonanza into a big nightmare.
It gets worse.
While sometimes data do sing and dance by themselves, we still live in a world where specialists must cajole incomplete, poor and inconclusive data into producing useful signals, metrics and other distilled pieces of information. This process is called various names such as: analytics, modeling, quantitative analysis, rocket science or just data science voodoo… This step is also fraught with risks, actually significantly higher risks than those linked to the quality of the raw data.
Namely it is a virtual certainty that if you:
give the exact same data set to two different analysts, they will produce different models, metrics and decisions
The promotion of artificial intelligence and machine learning as the great untapped quantification programme of humanity leads to uncharted territory where not only will model outcomes be different, the analysts might have no idea why this is so!
The Linked Data Solution
There is actually an (almost) magic wand to solve the data problem. The prosaic, old style (concise) hint is: Metadata, or data about data. There is a more comprehensive, forward looking and informative name, namely .
Conceived by none other than Tim Berners-Lee (the same person who brought us the Web itself (on which you read this post) Linked Data helps solve (or at least significantly contain) the data interpretation and provenance problems by elevating data into first class citizens in an interconnected web.
In the Linked Data architecture data are not just blobs of digital information floating around. They get to have a (web) name and address, a full bio, including pedigree and friends. There is a growing and maturing set of tools that can be used to aggregate, query and use such metadata.
The good news is that this technology is vital for the broader economy, that it will certainly find increasing support and development irrespective of adoption in the financial industry. The bad news is that Linked Data do not sing and dance by themselves either. While with the adoption we might be well on our way towards taming data management, data invariably get fed into quantitative models of various sorts and the corresponding status of Model Governance is far less advanced and fragmented across domains and verticals.
The Linked Models Solution
The challenge around governance and management of quantitative models is huge: we do not even have a good definition of what a model is.
- Is an excel sheet a model?
- Is an excel sheet a different model after you hit the F9 key? (think about this one).
- Is the napkin where the CEO scribbled the ball-park economics of a business deal a model?
- Is a procedure stored in a vendor database system a model?
- Is a calculation done in a Bloomberg terminal a model?
- Is the expert opinion of room full of silver haired individuals a model?
- What if said experts express their opinion as a quantitative score or rating?
The problem is that models of one sort or another are so useful and ubiquitous, they are all over the place. In fact computer scientists will call the mere schema of a database a data model thereby adding to the confusion of model definition.
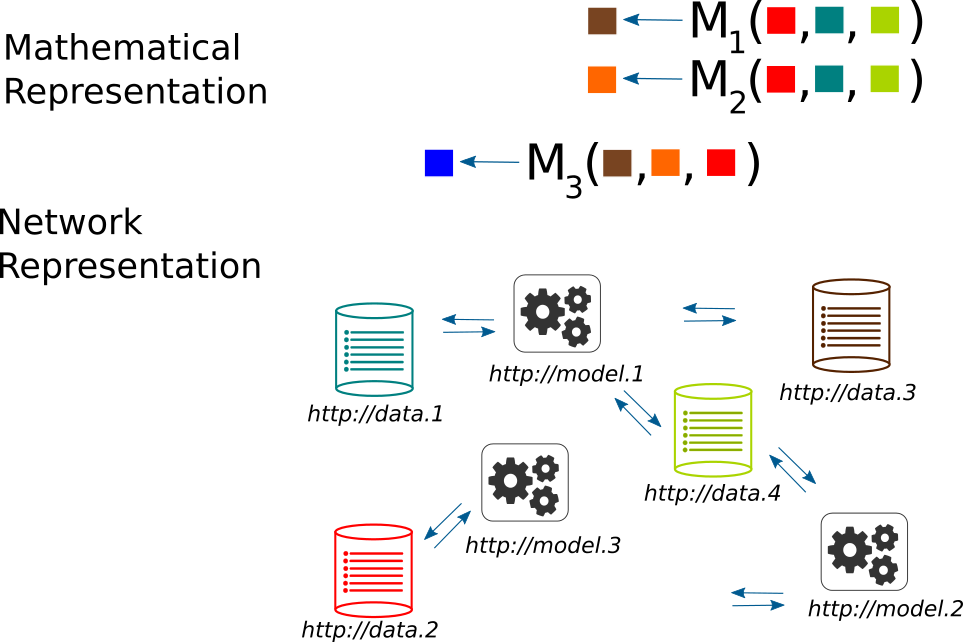
The solution we are proposing for the modeling side of data science is not unlike the Linked Data based solution to the data side. Namely we promote models to be first class citizens in an interconnected web:
A Linked Model is a model that has a name and an address, a full bio, including pedigree and friends
Hence, away with napkins, sheets and throwaway models of any sort if you don’t want to be facing a calamity a few years down the line. But let us be a bit more specific.
A Linked Model is not one but three (3) things at the same time. We call this DOAM (semantic Description Of A Model):
- There is an abstract model: captured and represented as human oriented knowledge in a paper. This is typically the description of a general Function, a mathematical entity that takes specific Linked Data as input and produces specific Linked Data as output. This human oriented model description is available somewhere on the web, although it may be private. It may even be machine readable / translatable into code.
- There is the model source code: the pieces of programming that are required to implement an abstract model, again available somewhere on the web. Again such implementations may be private or public.
- There is the model instance: this is the actual application that executes the model source code (produces live results), for example available (via an API) somewhere on the web.
The metadata technologies required for implementing Linked Models are similar to - but extending - those pertaining to Linked Data. They also overlap with so-called Service Oriented Architectures (SOA), but place more emphasis on documenting and making accessible the mathematical content of the data processing function of the model.
Interested in the Linked Models concept?
- Learn more about Linked Models in our presentation at the 2015 Dutch Central Bank / TopQuants meeting
- Interested to explore the Linked Models implementation of the OpenCPM? Let us know!