13, Techniques for Federated Analysis
Open Risk White Paper 13: Federated Credit Systems, Part II: Techniques for Federated Data Analysis
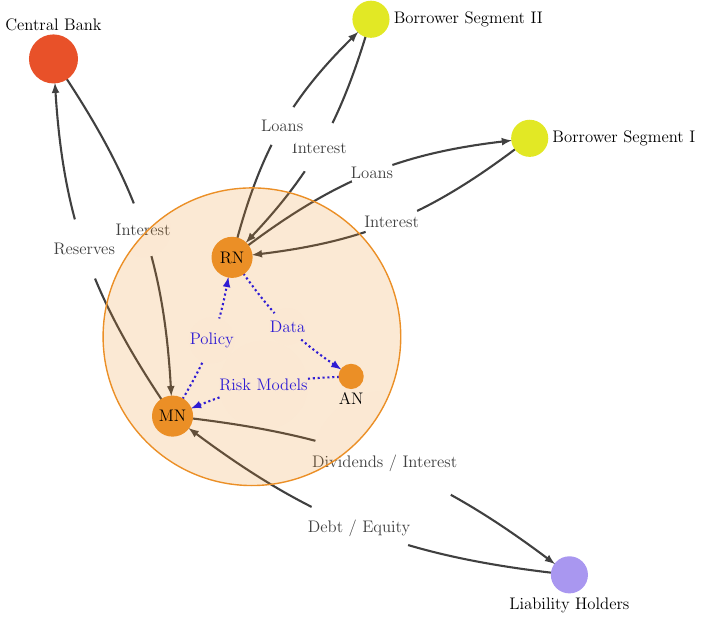
In this Open Risk White Paper, the second of series focusing on Federated Credit Systems, we explore techniques for federated credit data analysis. Building on the first paper where we outlined the overall architecture, essential actors and information flows underlying various business models of credit provision, in this step we focus on the enabling arrangements and techniques for building Federated Credit Data Systems and enabling Federated Analysis.