Federated Credit Risk Models
The motivation for federated credit risk models
Federated learning is a machine learning technique that is receiving increased attention in diverse data driven application domains that have data privacy concerns. The essence of the concept is to train algorithms across decentralized servers, each holding their own local data samples, hence without the need to exchange potentially sensitive information. The construction of a common model is achieved through the exchange of derived data (gradients, parameters, weights etc). This design stands in contrast to traditional model estimation where all data reside (or are brought into one computational environment).
Federated learning enables multiple cooperating actors to build a common model without sharing data, thus addressing critical issues such as data privacy and data security which are particularly strict in regulated industries such as banking. The benefits of this mode of federated risk model development should be particularly tangible in risk domains and use cases where risk data are relatively scarce. Examples of such conditions are abundant in credit risk applications, with the most extreme manifestation being the so-called low-default portfolios. Federated estimation of models can in such circumstances reduce or eliminate the data scarcity problem (under the assumption that on a pooled basis the available data are sufficient).
openLGD: an open source federated framework for the estimation of Loss Given Default models
openLGD is a Python powered library for the statistical estimation of Credit Risk Loss Given Default models. It can be used both as standalone library and in a federated learning context where data remain in distinct (separate) servers. The initial release demonstrates a basic federated estimation of an LGD model.
Demo LGD model and data
The implemented model of the initial release is a simple linear model with one explanatory factor (and synthetic data). Yet the implementation is sufficiently general (based on iterative stochastic gradient descent) that a large number of generalizations are possible.
The model estimation employs the concept of federated averaging. This is simply the averaging of model parameters ( as those are estimated iteratively) on the basis of sample size.
Setup to run the demo
- Clone the repo in a local linux environment (experienced used could probably reproduce this on a Windows environment)
- Install the dependencies (in a virtual environment)
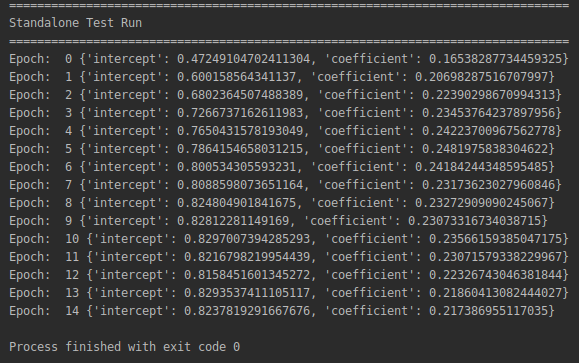
Perform a standalone run first. Make a standalone test run to ensure the local environment / paths / dependencies are properly setup.
- cd openLGD
- python standalone_run.py
You should get a screenshot like this, illustrating iterative estimation of the model on the basis of the standalone server data:
Spawn a model server cluster
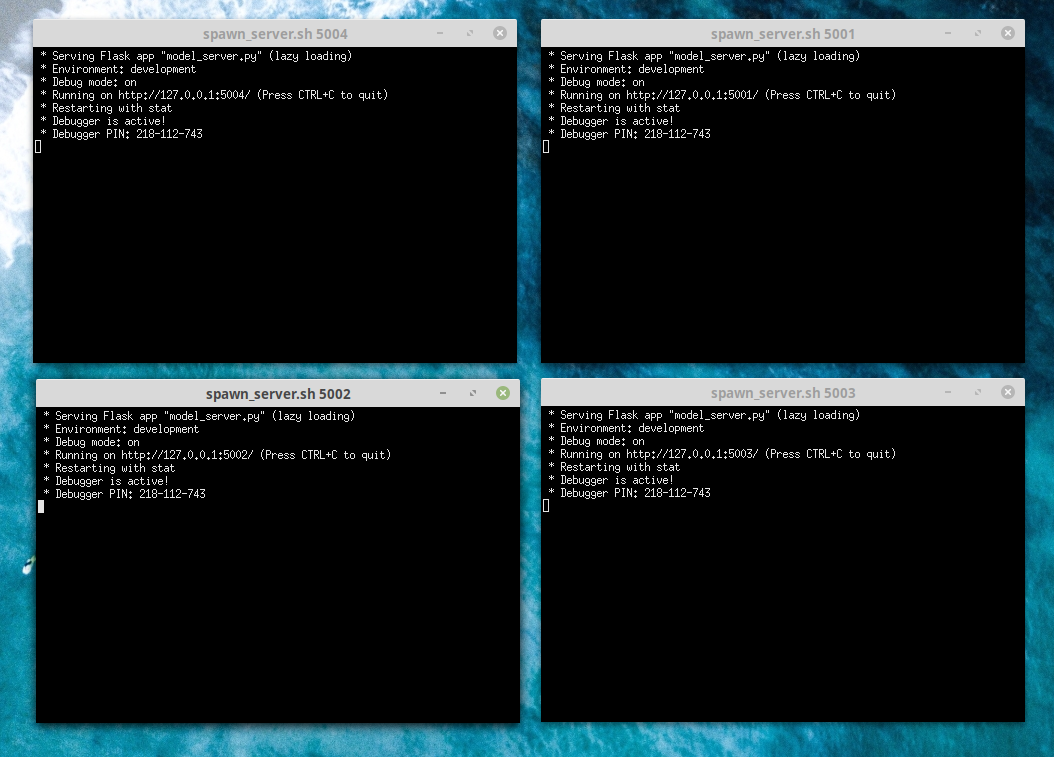
In order to make the demo easy to execute, we emulate a decentralized server environment (but all web servers are actually running on the same machine). In more realistic applications the data would be accessed from local databases. Here those are emulated with local filesystem storage under the server_dirs directory.
- Fire up a number of flask servers on different xterm shells.
- Run the Spawn Cluster Script
- The script uses ports 5001-5004. If by any change you are already using these ports you would need to adapt the script
- The model servers should start up on ports http://127.0.0.1:500X/ where X is the serial number
- You can check the servers are live by pointing your browser to the ports
- or by using curl from the console (curl -v http://127.0.0.1:500X/)
If all goes well you should get four xterms with a flask server active in each one.
Model Server API endpoints
The general structure of the simplified API is of the form
- GET http://127.0.0.1:500X/ API Root, indicating the server is live
- GET http://127.0.0.1:500X/start URL to get initial locally estimated parameters (cold start)
- POST http://127.0.0.1:500X/update URL to post current averaged parameters (warm start)
Run the federated LGD model estimation
- Run the federated_run script to perform the federated estimation calculation. If all goes well you should get the following screenshot:
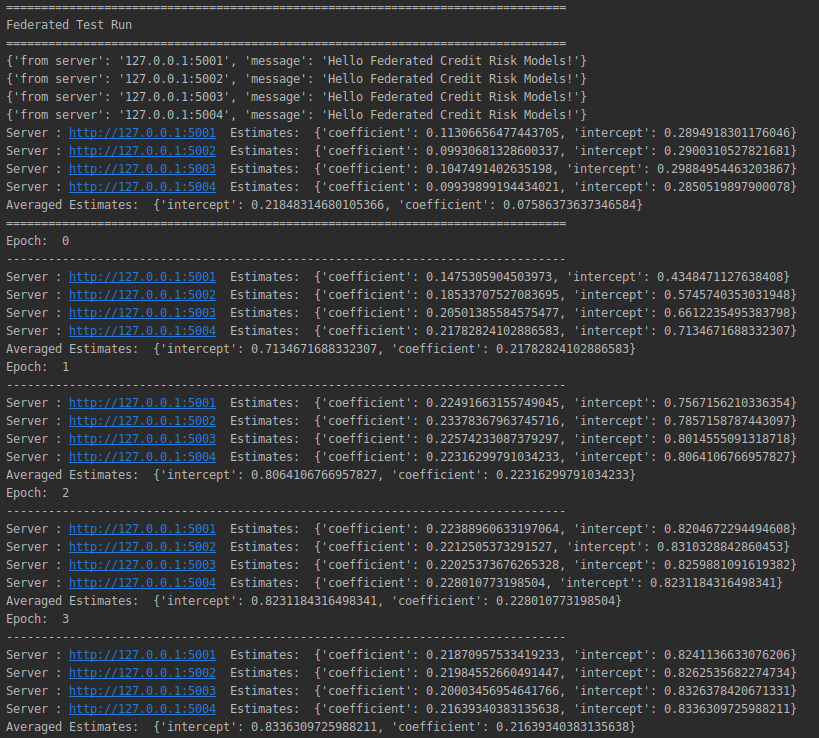
Hello Federated Credit Risk Models
- Well done!
- The first messages confirm the servers are live and print the first local estimates send to the coordinating node
- Subsequent blocks show a number of iterative estimates (epochs) where the averaged model parameters are send back to the local servers and used to obtain the next local estimate
Conclusion, Challenges and Next Steps
The demo included in this first release of openLGD illustrates the feasibility of solving a longstanding problem plaguing the development of credit risk models (and loss-given-default models in particular), namely the adequacy of risk data for the robust estimation of models. Using open source libraries for machine learning and web server data exchange it is possible to design iterative estimation algorithms that converge towards a federated model without the exchange of actual data (only model parameters). Such federated models can then be used by participating actors as improvements or benchmarks to the standalone developed models.
The development of federated credit risk models still requires that the entities participating in the network agree to share substantial information that is (normally) internal. This includes, for example, variable vocabularies that would enable the mapping of internal data to a common data model and (in the federated averaging approach) information about sample size. Further, as the data are never shared, there is no validation and a malicious or negligent participant could compromise the quality of federated model
The adoption of open source, federated credit risk models that pool risk information without compromising data privacy could give a substantial boost to the quality of quantitative models. Interested parties who would like to explore the concept further are encouraged to get in touch.
Comment
If you want to comment on this post you can do so on Reddit or alternatively at the Open Risk Commons. Please note that you will need a Reddit or Open Risk Commons account respectively to be able to comment!