Representing a Sparse Matrix as a JSON object is a task that appears in many modern data science contexts. While there is no universally agreed way to achieve this task, in this post we discuss a number of options and the associated tradeoffs.
Recap of Part 1 of the Matrix-to-JSON Post Series In the first installment of this series, Part 1 we discussed the motivation behind representing and serializing matrices as JSON objects. We defined relevant concepts and in particular the concept of unrolling the matrix into a one-dimensional array and the notion of Column and Row Major orders. We outlined some use cases of interest and initiated a benchmarking exercise that looks into various R and Python JSON serialization utilities (available at the matrix2json repository).
An Awesome List for Sustainable Finance. Awesome Sustainable Finance is a curated list of sustainable finance resources. The focus of the list is on code (tools, libraries, frameworks etc.) that fairly directly support any type of sustainable finance effort but also open data that are useful in a sustainable finance context.
Image Credit: StarwallOfRadical.town, CC BY-SA 4.0, via Wikimedia Commons
How to Contribute The list is maintained on github so the easiest way to contribute is to open a Pull Request in our repository.
New data models introduced in this release of Equinox cater to the requirement of integrating energy attribute certificate information into the portfolio database.
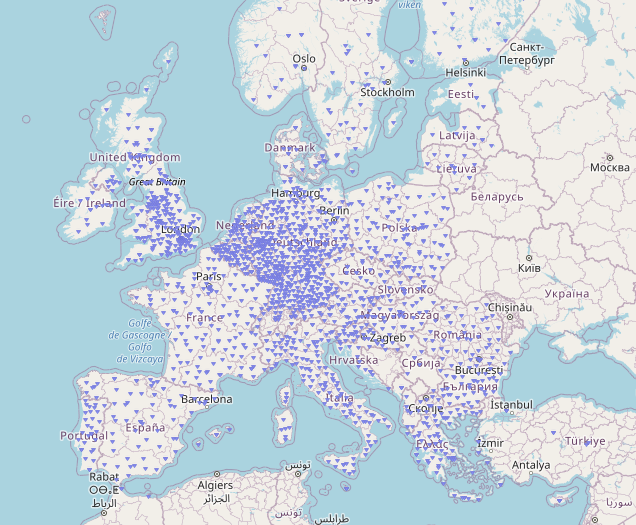
GHG Accounting offers a means of measuring the direct and indirect emissions to the Earth’s Biosphere of CO2 and its equivalent gases from industrial and other activities. GHG Accounting is a rapidly developing area that has come to receive increased focus in the context of accelerating Climate Change. Given that the generation of electricity and heat accounts for around a third of global GHG emissions electricity consumers have incentives to proactively reduce those emissions by reducing electricity demand, or by shifting energy supply by procuring alternative lower-carbon or renewable resources.
Solstice is a flexible open source economic network simulator. Its primary outcomes are quantitative analyses of the behavior of economic systems under uncertainty. In this post we provide a first overall description of Solstice to accompany the first public release.
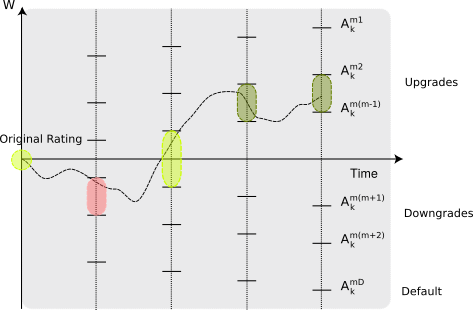
Modeling economic networks and their dynamics Economic networks are the primary abstractions though which we can conceptualize the state (condition) and evolution of economic interactions. This simply reflects the fact that human economies are quite fundamentally systems of interacting actors (or nodes in a network) with transient or more permanent relations between them.
In practice the network character of an economy is frequently suppressed or under-emphasized and does not play a particularly important role.
In the fourth part of this series we approach Green Public Procurement as a Sustainable Portfolio Management task and explore how open data can support this mission
Introduction In this fourth and final installment we will discuss how the data framework we have developed thus far can be mapped into classic portfolio management concepts and categories, and thus, how one can articulate the concept of sustainable procurement management on a portfolio basis. The concepts and analytic methodologies of financial portfolio management1 can significantly enhance the toolkit available to practitioners and, in sense, connects the domain of Green Public Procurement to other ongoing initiatives in broader Sustainable Finance.
In the third part of this series we illustrate how one may assign greenhouse gas emissions to public procurement using environmentally extended input-output models
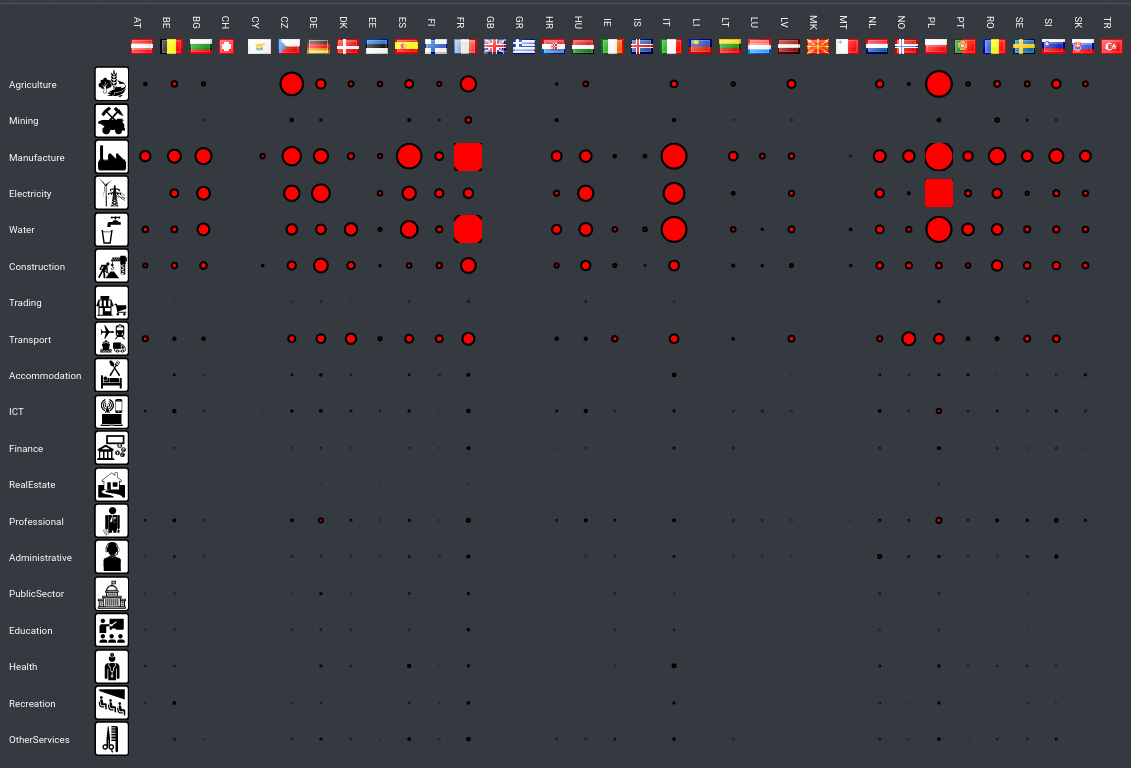
Introduction This is the third in a series of posts where we explore the role of Open Data and Open Source in enabling and accelerating the broad based effort towards Green Public Procurement (GPP). In this third installment we will link procurement entities to private sector sellers and, through the sectoral profile of the procurement contract, (CPV category) we will infer the amount of CO2 emissions that can be attributed to these activities.
Introduction This is the second in a series of posts where we explore the role of Open Data and Open Source in enabling and accelerating the broad based effort towards Green Public Procurement (GPP).
Recap of the Previous Post Part 1 - Overview In the first part of this series we motivated and defined the scope of a study that explores Public Procurement data. We discussed the meaning of the main relevant terms (Open Data, Open Source, Green Public Procurement) and briefly reviewed the current state and challenges of the latter in EU context.
In the first part of this series we survey the TED procurement data landscape to build the context in which we will explore the relevance of this open data set for green public procurement
Introduction In a series of posts we will explore the role of Open Data and Open Source in enabling and accelerating the broad based effort towards Green Public Procurement (GPP). There are several important (and possibly obscure) terms in this sentence, so our first order of business will be to unpack them.
What is Public Procurement Let us start with the term Public Procurement which will be the main domain of interest in this study.
We are very happy to announce that our EU Datathon 2022 proposal based on the equinox platform has been pre-selected to enter the formal stage of the competition
What is the EU Datathon? The EU Datathon is an annual Open Data competition organised by the Publications Office of the European Union since 2017. The competitions are organised to create new value for citizens through innovation and promoting the use of open data, in particular the datasets available on the official portal for European data.
Every year, EU Datathon calls for innovators from around the world to come up with new ways of using open data to address important societal and environmental challenges, with the condition that they use at least one of the thousands of data sets published on data.
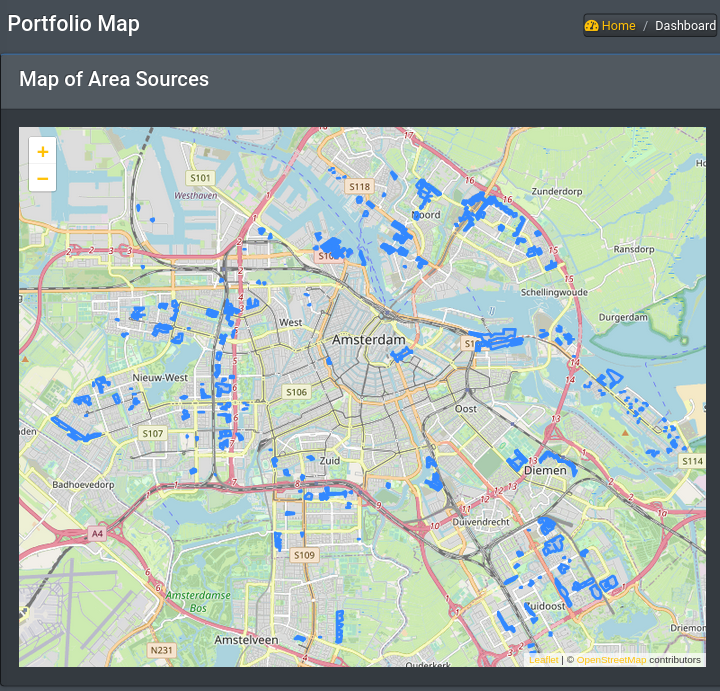
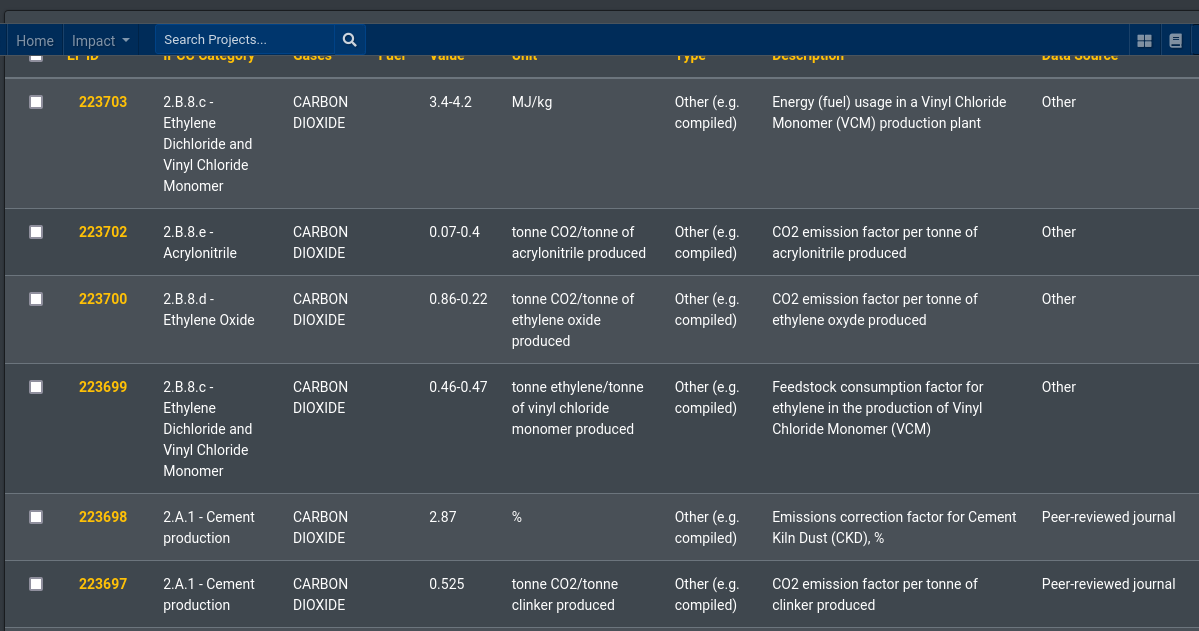
Equinox 0.4 Release Equinox is an open source platform that supports holistic risk management and reporting in the context of Sustainable Portfolio Management. The platform integrates geospatial information with applicable regulatory and industry standards, for example the GHG Protocol (accounting for Project based, Corporate and City-Wide greenhouse gas emissions), the IPCC Emissions Factor database and further reference data, the PCAF attribution methodologies (and more) to provide a holistic view of the footprint of both individual projects and portfolios.
Representing a matrix as a JSON object is a task that appears in many modern data science contexts, in particular when one wants to exchange matrix data online. While there is no universally agreed way to achieve this task in all circumstances, in this series of posts we discuss a number of options and the associated tradeoffs.
Motivation and Objective Representing a Matrix as a JSON object is a task that appears in many modern data science contexts, in particular when one wants to exchange matrix data online in a portable manner. There is no universally agreed way to achieve this task and various options are available depending on the matrix data characteristics and the programming tools and computational environment one has available.
Matrices are not, in general, native structures in general purpose computing environments.
In the latest update of the Equinox Project we discuss the integration of reference data an in particular greenhouse gas emissions factors as catalogued in the IPCC Emissions Factors database (EFDB).
Equinox is an open source platform that supports the holistic risk management and reporting of major sustainable finance projects (the financing of projects with material physical footprint) such as project finance. Equinox aims to integrate in the database a number reference databases that facilitate tasks of sustainable portfolio management. In the current focus such reference material concerns the emissions factors for various processes and activities. In the latest (Solstice Day!
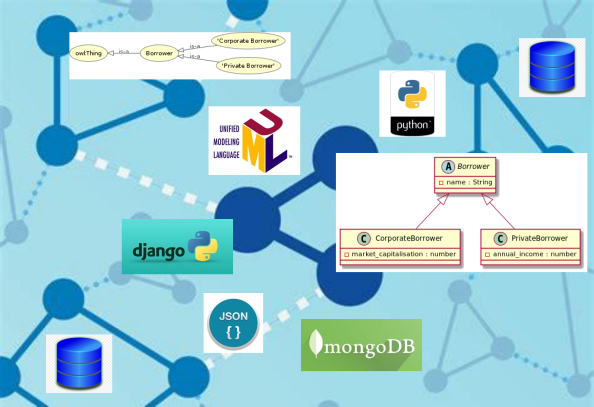
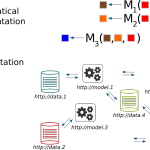
Object-oriented programming and techniques (OOP) such as using classes and inheritance are common in many application programming environments but don't travel well outside computer memory. When considering data science tasks and objectives the transition from object hierarchies to data structures (and vice versa) is not always straightforward. In this short course we explore how some programming languages, data formats, database API's and web frameworks handle hierarchical classes.
Summary In this short course we explore how some programming languages, data formats, database API’s and web frameworks handle hierarchical classes.
Content Object-oriented programming and techniques (OOP) such as using classes and inheritance are common in many application programming environments but alas don’t “travel well” outside computer memory. The potentially intricate relationships of objects (both the data they hold and the meaning and possible uses of the data) are not easy to transfer (except of-course by full replication of code and data).
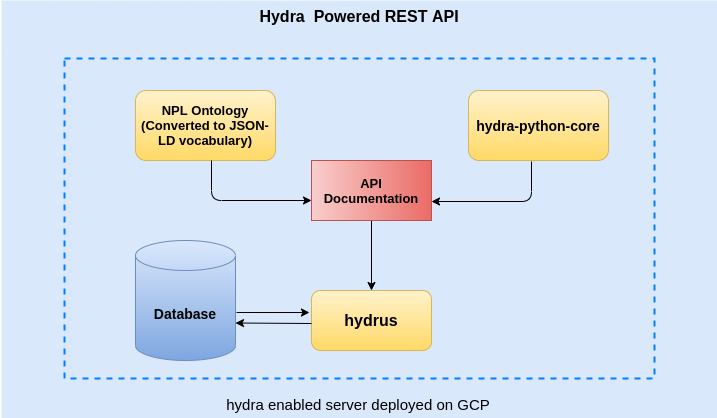
The GSOC 2021 collaboration between Open Risk and the Hydra Ecosystem - Project Wrap-Up Google Summer of Code 2021 came and went amid the still ongoing worldwide pandemic experience. Open Risk was happy to join forces with the Hydra Ecosystem in exploring a proof-of-concept for next generation API’s using Hydra.
The project aimed to guide students (here and here) to build a hypermedia enabled REST service that can serve standardized credit portfolio data.
For the Google Summer of Code 2021 season Open Risk is happy to join forces with the Hydra Ecosystem to mentor a student project that aims to build a hypermedia enabled REST service around standardized credit portfolio data
A GSOC 2021 summer project collaboration between Open Risk and the Hydra Ecosystem Summer is underway and for the Google Summer of Code 2021 season Open Risk is happy to join forces with the Hydra Ecosystem. The project aims to guide students to build a hypermedia enabled REST service around standardized credit portfolio data. More specifically the project will build a REST service as backend for a hypothetical banking entity that collects and disseminates credit portfolio data conforming to an established public standard (the EBA NPL templates, see below).
Equinox is an open source platform that supports holistic risk management and reporting of Sustainable Finance (Sustainable Portfolio Management). The platform integrates geospatial information with applicable regulatory and industry standards from EBA, PCAF and Equator Principles to provide a holistic view of the footprint of both individual projects and portfolios, in particular of project finance investments. Motivation Sustainability (understood in environmental, economic and social terms) is emerging as an undisputed constraint that will shape future human activity and more specifically how the financial system facilitates and empowers economic life.
Semantic Web Technologies integrate naturally with the worlds of open data science and open source machine learning, empowering better control and management of the risks and opportunities that come with increased digitization and model use The ongoing and accelerating digitisation of many aspects of social and economic life means the proliferation of data driven/data intermediated decisions and the reliance on quantitative models of various sorts (going under various hashtags such as machine learning, artificial intelligence, data science etc.
Celebrating Pi Day 2021 Pi Day is celebrated every year on March 14th. The reason of course is that the day is denoted in some calendars as (3/14), which evokes of 3.14, the first three digits of “π”. A thin excuse maybe but sufficient for the true believers to join along! The occasion represents an annual opportunity for mathematics and science enthusiasts to recite the infinite charms of Pi, including its irrationality, to talk to friends and family about math and its uses, and, when everything else fails, simply eat pie.
Course Content This CrashCourse is an introduction to semantic data using Python. It covers the following topics:
We learn to work with RDF graphs using rdflib We explore the owlready package and OWL ontologies We look into json-ld serialization of RDF/OWL data We try data validation using pySHACL We use throughout a realistic data set based on the Credit Ratings Ontology Who Is This Course For The course is useful to:
The Non-Perfoming Loan Ontology The Non-Performing Loan Ontology is a framework that aims to represent and categorize knowledge about non-performing loans using semantic web information technologies. Codenamed NPLO, it codifies the relationship between the various components of a Non-Performing Loan portfolio dataset.(NB: Non-performing loans are bank loans that are 90 days or more past their repayment date or that are unlikely to be repaid, for example if the borrower is facing financial difficulties).