Towards the Semantic Description of Machine Learning Models
Semantic Web Technologies integrate naturally with the worlds of open data science and open source machine learning, empowering better control and management of the risks and opportunities that come with increased digitization and model use
The ongoing and accelerating digitisation of many aspects of social and economic life means the proliferation of data driven/data intermediated decisions and the reliance on quantitative models of various sorts (going under various hashtags such as machine learning, artificial intelligence, data science etc.).
Realizing the opportunity and managing the risks associated with this epochal transition into a more profoundly quantified / digitized society requires powerful new behaviours and tools:
In this post we develop further the concept of semantically described quantitative models with a new release of the Risk Model Ontology. This ontology is a framework that aims to represent and categorize knowledge about risk models using semantic web information technologies. Codenamed as the Description of a Model (DOAM) it codifies the relationship between the various components of a risk model universe. The initial DOAM releases developed high level context for the description of models, with this release we start the process of including more detailed low level information.
Predictive Models
One of the most important classes of models used in practice in risk management (but also many other domains) are so-called predictive models. As with every other aspect of the data science and machine learning universes, the perimeter of what is a predictive model is not very clear. It broadly encompasses the range of regression and classification models (including tools such as scorecards, neural networks and other supervised learning algorithms).
Very importantly for our purposes, there is a fairly broad-based industry effort to describe predictive models using a defined Markup Scheme . The Predictive Model Markup Language (PMML) is an XML-based predictive model interchange format conceived some time ago by Dr. Robert Lee Grossman. PMML provides a way for digital computers to describe and exchange information about predictive models produced by data mining and machine learning algorithms. With a sufficiently detailed description (and some further implied assumptions about the meaning of such data) two completely distinct infrastructures can implement and deploy the same conceptual and mathematical procedure.
PMML currently supports many common models such as logistic regression, bayesian networks, support vector machines and feed-forward neural networks. It is a long-standing effort: Version 0.9 was published back in 1998. Subsequent versions (the latest as of April 2021 is 4.4) have been developed by the Data Mining Group.
PMML uses XML to represent mining models. The structure of conforming PMML model documentation is described by an * XML Schema*. One or more mining models can be contained in a PMML document. In a nutshell,
- Model producers (e.g. a quantitative library or other framework that estimates a model using data) export a sufficient set of codified information into a PMML file.
- Model consumers (e.g. a production engine used to predict or forecast on the basis of new data) imports the PMML file and implements the estimated model.
There are currently several platforms that support PMML, including open source python libraries such as Scikit-Learn.
The essence of the PMML specification is an XML Schema. An XML schema is a description of a constrained class of XML documents expressed in terms of restrictions on the structure and content of documents conforming to that class (besides the requirement to be a valid XML file). Constraints are generally expressed using rules governing the order of elements that can appear, predicates that the content must satisfy, the permissible data types of elements and attributes etc.
As a very quick example, the constrained shape of a PMML document fragment introducing a new model might look something like this:
<xs:element name="ExampleModel">
<xs:complexType>
<xs:sequence>
<xs:element ref="MiningSchema"/>
<xs:element ref="Output" minOccurs="0"/>
<xs:element ref="ModelStats" minOccurs="0"/>
<xs:element ref="Targets" minOccurs="0"/>
<xs:element ref="LocalTransformations" minOccurs="0" />
...
<xs:element ref="ModelVerification" minOccurs="0"/>
<xs:element ref="Extension" minOccurs="0" maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute name="modelName" type="xs:string" use="optional"/>
<xs:attribute name="functionName" type="MINING-FUNCTION" use="required"/>
<xs:attribute name="algorithmName" type="xs:string" use="optional"/>
<xs:attribute name="isScorable" type="xs:boolean" default="true"/>
</xs:complexType>
</xs:element>
Skipping (many, many) details, we see in the above snippet a defined nested structure that associates a sequence of components (elements) such as Output and ModelStats with the ExampleModel. We see also attributes such as modelName and isScorable.
An Ontology for Predictive Models
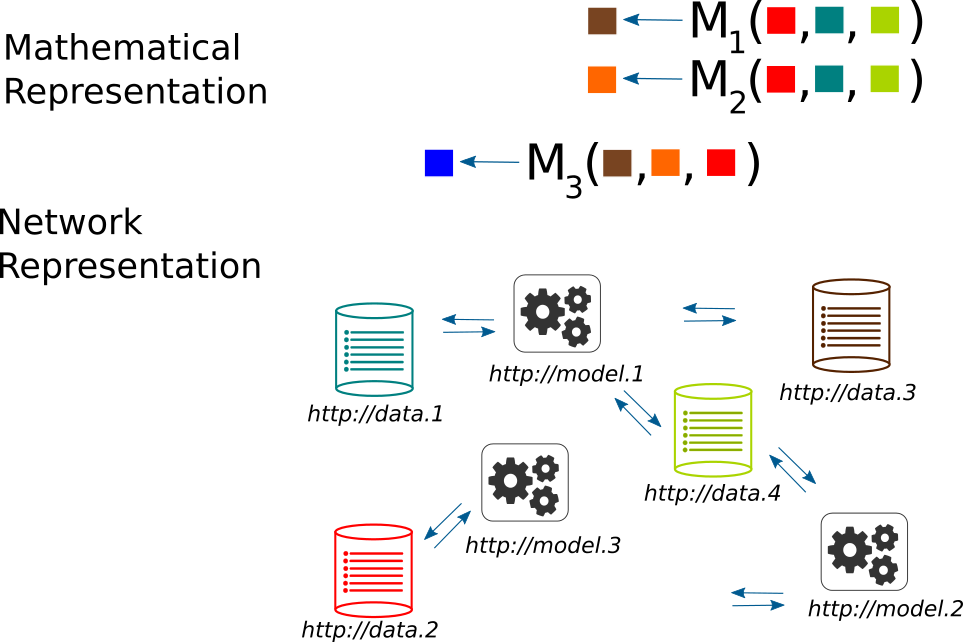
The use of XML Schema is a flexible and powerful way to describe the complex structure of a predictive model. What it does not provide is easy mechanisms to overview and probe deeper into model structures and relations between models. Such deeper insights within and across multiple models is what is generally needed when we enter into the domain of Model Risk Management where we tend to think in terms of a model portfolio (a collection of number of distinct models).
It is at this stage where the related (but distinct) set of RDF/OWL schemas and semantic technologies have an edge over XML/XSD. We next proceed to illustrate how we can integrate the two worlds. It is important to state right away some significant design issues:
- There is no unique way of transposing an XML Schema to an OWL ontology. The two systems have substantial differences both conceptually (the type of logical relationships and constraints they envisage) and practically e.g., how concrete datatypes are represented and utilized. For example, structured numerical datatypes such as simple or more complex arrays are not particularly meaningful (pun) in an OWL ontology context and thus are not supported.
- The semantic representation of predictive models that are already expressed via the PMML schema is by necessity
opinionated (as in: it injects particular preferences in relation to anticipated uses). One could for example
- adopt a bottom-up approach, aiming to establish a lower-level correspondence that focuses on transposing the patterns found in the PMML schema into RDF graph relations or
- a top-down approach, focusing on common conceptual patterns of a “model universe”.
- In practical usage, a model (or model set) represented using PMML is a valid XML document that is also conforming to a (separate) XML Schema. In contrast, a set of concrete assertions about a model landscape are captured in DOAM as a valid OWL document (expressed, e.g., in RDF/XML) which will include concrete estimated models as instances of classes that conform to the ontology.
With those clarifications and caveats, let us dive in into what Predictive Model semantics is included in the 0.4 release of the DOAM ontology (Given that predictive models is but one type of models that are useful in risk management context the aim is to expand DOAM with further detailed model categories).

First a brief recap of the core DOAM ontology concepts. There are three key elements to the DOAM ontology (as with any ontology):
- The DOAM Classes (Concepts) that define the relevant aspects of the Risk Model Universe: The choice of classes
defines the scope of this knowledge domain. The current high level classes are:
- Risk Model, is the core class that is the subject of the ontology
- The Abstract Risk Model, the conceptual definition of the model. A Predictive Model is a subclass of an Abstract Model
- The Model Specification, a concrete specification of a model that populates any information placeholders defined in the Abstract Risk Model description
- The Model Implementation, the computer programs and any other resources required to operate the model
- The live Model Instance that is deployed in operation (production)
- A risk model category as part of a Model Taxonomy to which the model belongs
- A model scope
- A Code Repository
- The DOAM Object Properties (Relationships between classes / concepts). Object properties relate individual
instances of two OWL classes: e.g. A Model has a Model Validator. Examples of high level object properties:
- hasTester
- hasModelCategory
- hasRepository
- hasMaintainer
- hasDocumenter
- hasDeveloper
- hasAuthor
- etc
- The DOAM Data Properties (Data literals associated with classes / concepts). Datatype properties (owl:
DatatypeProperty) relates individuals (instances) of the DOAM OWL classes to literal values. e.g. A Model has a
required Data Input. Examples of data properties:
- creationDate
- dataEndPoint
- documentationURL
- repositoryURL
Predictive Model Classes, Object and Data Properties
The High level DOAM classes that target the PMML schema are:
- Abstract Model
- Predictive Model
- AnomalyDetectionModel
- AssociationModel
- BaselineModel
- BayesianNetworkModel
- ClusteringModel
- DecisionTree
- GaussianProcessModel
- GeneralRegressionModel
- MiningModel
- NaiveBayesModel
- NearestNeighborModel
- NeuralNetwork
- Regression
- RegressionModel
- RuleSetModel
- Scorecard
- SequenceModel
- SupportVectorMachineModel
- TextModel
- TimeSeriesModel
- TreeModel
- Predictive Model
Model Components come in two categories:
- Model Components that are shared between two or more Abstract Models, e.g.
- MiningSchema
- ModelStats
- Targets
- etc
- Model Components specific to a PMML model type, e.g.
- NeuralLayer component of NeuralNetwork
- TextDictionary component of a TextModel
- Characteristics component of a Scorecard
- etc.
Similarly, Model Class Attributes come in general and specific categories:
- Model Attributes that are shared between two or more Abstract Models, e.g.
- modelDescription (String)
- isScorable (boolean)
- etc
- Model Attributes specific to a PMML model type, e.g.
- numberOfNeighbors attribute of NearestNeighborModel (integer)
- linkFunction attribute of GeneralRegressionModel (string)
- etc.
You can explore more the latest version of DOAM here
Current Use of DOAM
DOAM is embedded and used in the Open Risk Manual and associated Open Source Projects
- Various risk manual entries (pages) serve as additional documentation (annotation) of DOAM elements (the relevant page is indicated / linked to via rdfs:seeAlso annotations in the DOAM file itself)
- Open Source Risk Models (such as transitionMatrix) use manual entries as the definitive Abstract Risk Model documentation page
- The DOAM ontology is imported to use by the semantic mediawiki extension of the Open Risk Manaul (enables more sophisticated queries)