Visual Overview of Built-In Python Data Types
We discuss the Python language built-in data types and a visualization that organizes them according to key attributes
Data Types are a fundamental building block of data science
Data science is about data, but data are not simple and tame beasts. They have character and attitude, which can cause a lot of friction between them and the data scientist. There is a lot of sweat and tears involved when confronting data, but data scientists can do worse than know how to handle in particular Data Type quirks. Namely, a good fraction of data science involves not modelling data, not transforming data, not even cleaning data but simply goading data around the right containers, providing them with the right stage that fits their character. Getting the data type wrong is many a source of both spectacular bugs and hidden, insidious application errors.
When programming digital computers, a data type is the attribute of a variable that determines what kind (shape) of data it can hold. Is it a “number”?, what kind of number? etc. How does this diversity of data personality come about? At the lowest level all data are actually siblings, fairly uniform and rather boring. In the end it is all about zeros and ones living either in some chip, or some storage device, or momentarily in transit via some digital network. But, at the level at which developers and data analysts actually work they face the cumulative outcome of a large number of architectural decisions about hardware and software components. These decisions shape the precise nature of data that can be passed around.
Why data types are such a mess
Starting at the lowest level of information technology infrastructure we have over the decades evolving chip
architectures (starting with 8 bit
for the first widely available chips and dominated
by 32 bit and 64 bit in current technologies). This background already
places some fundamental constraints in how data types are structure. This may sound a bit esoteric but can seriously
affect “end-user” data science applications. For example many algorithms require double precision accuracy
to ensure that growing errors in the calculation chain do not
prevent convergence to the correct result.
Moving up the ladder we have the data shapes commonly available within database systems, programming languages, communication protocols etc. The cumulative outcome of this interlocked stack of technology layers is that the same " piece of information" can have different “faces” or digital footprints, depending on where it lives and as it is being transmitted back and forth.
In this post we undertake a brief exploration of data personalities within the Python universe. It is by no means exhaustive (we leave out topics such as e.g. string internationalization) but it should give a flavor why it data types is an important topic to master early on.
The Important Data Type attributes
Before we enumerate and try to visualize the logical relations of the Python data types, let us review what are some attributes that distinguish data types:
- Mutable / Immutable: whether a variable / object can change after it has been created
- Iterable / Non-iterable: whether a variable / object can be accessed as a sequence of more fundamental elements
- Hashable / Non-Hashable: whether a variable / object is usable as a dictionary key and a set member
Built-in Types
The core built-in data types of Python are classified in the following four groups:
- Numerics
- Sequences
- Sets
- Mappings
More complex data types that we will not discuss here are: Classes, Instances and Exceptions. By combining complex and elementary data types one can implement any desired data structure.
1. Numeric Types
There are three distinct built-in numeric types:
- Integers, Floating point numbers, and Complex numbers.
- In addition, Booleans are a subtype of integers.
Most people using Python even at a very basic level would be familiar with integers and floats but it is worthwhile noting that complex numbers are also a built-in type.
2. Sequence Types
The are general sequence types (list, tuple):
- List: Lists are mutable sequences, typically used to store collections of homogeneous items
- Tuple: Lists are immutable sequences (but see an exception)
And special sequence types (strings and bytes)
- Str (String): Strings are immutable sequences of Unicode elements
- Bytes: A bytes object is an immutable sequence of integers in the range 0 <= x < 256
- Bytearray: Bytearray objects are a mutable counterparts to bytes objects
3. Set Types
There are two Set Types, the set and the frozenset
- Set: A set object is an unordered collection of distinct hashable objects
- Frozenset: A frozenset is an immutable version of the set
4. Mapping Types
A mapping object maps hashable values to arbitrary objects. The main Python mapping type is the dict.
A visual overview
We can put all the above information in a diagram the sorts data types according to the attributes we discussed:
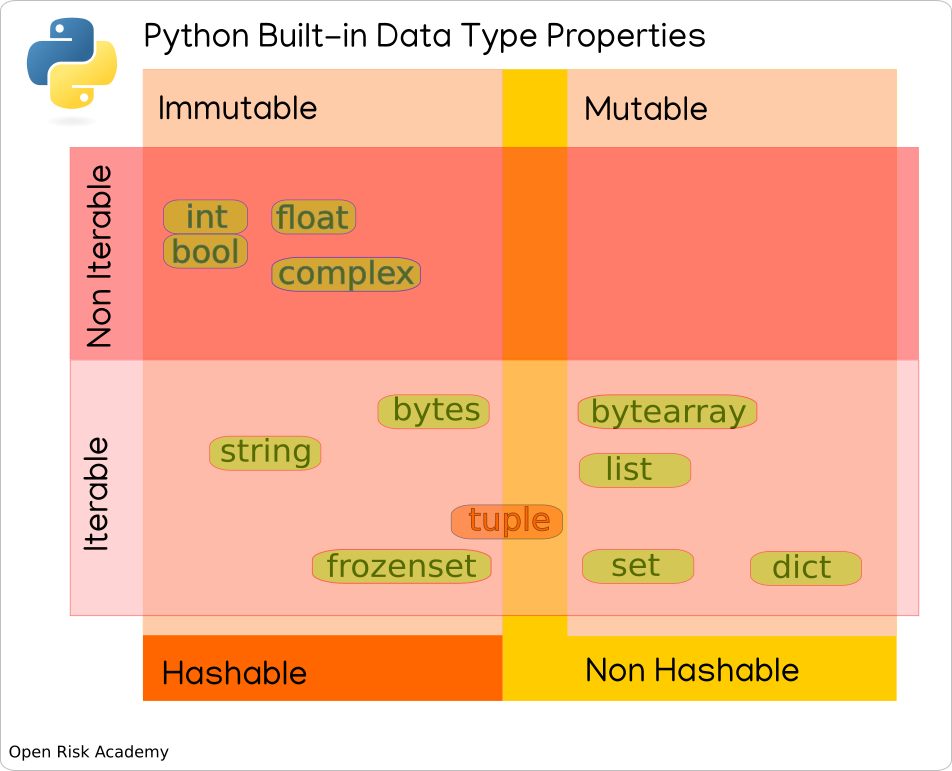
Mutable objects versus Immutable objects
The left / right dimension of the diagram differentiates objects according to mutability:
- Mutable: list, dict, set, byte array
- Immutable: int, float, complex, string, tuple, frozen set, bytes
Iterable objects versus non-iterable objects
The up / down dimension of the diagram differentiates objects according to iterability:
- Non-iterable: int, float, bool, complex
- IterableL: string, bytes, tuple, frozenset, bytearray, list, set, dict
Hashable objects versus non-hashable objects
Hashability and mutability are closely linked. Most of Python’s immutable built-in objects are hashable.
The important exception is that immutable containers (such as tuples and frozensets) are hashable if their elements are hashable.
Further Reading
The Python documentation describes data types and their properties primarily in those two pages:
Python is an important tool for risk management oriented data science. A number of related courses (open and freely available) can be found in the Open Risk Academy Course Catalog