Why are there so many concentration indices?
We discuss the proliferation of indices and metrics for computing concentration risk (and related diversification and inequality indices). We go over underlying reasons for such proliferation.
Summary
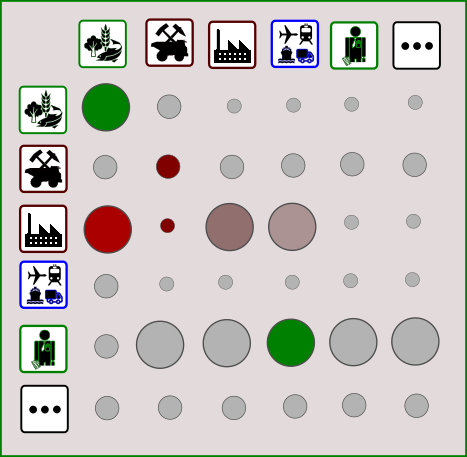
There are dozens upon dozes of indices that aim to measure concentration risk (and related concepts such as diversity or inequality). Why such a proliferation of alternatives? There are multiple reasons, which we will attempt to identify in this post. This enumeration prompts us to dig deeper into the nature of concentration indices and their various pros and cons.