Privacy-at-Risk
The Data Privacy genie is out of the bottle
From Yahoo’s massive email data leaks, to Equifax’s exposing of sensitive data for a large segment of the US population, to Apple’s resisting the bypassing the security features of the iPhone, not a week goes by without some alarming piece of news around data privacy.
The ramifications for the legal use of private digital data by companies and government and the consequences of illegal or unintended use are huge. We have all the ingredients for a very potent risk cocktail that threatens to inflict our increasingly digitally oriented societies with a nasty hangover.
The risk management of digital privacy is of double interest for the financial services sector. The industry routinely handles large volumes of private data hence it is vitally affected itself, and as the process of digitization gathers pace it is increasingly exposed to this type of risk. On the other hand, the financial sector already has among the most comprehensive frameworks for managing other types risks and hence may have a constructive role to play.
Risk Management tools that help put things in perspective
One key feature of modern risk management frameworks is the handling a multitude of risks. While individual risk assessment is enough of a challenge in itself, in practice there is always the additional challenge of
making practical sense of, and getting on top of, the entire range of coupled risks linked to digital privacy
One of the enduring legacies of financial risk management is the idea that we can organize our thinking around risks by sketching out the likelihood and impact of different scenarios in a loss distribution.
In its simplest form it works as follows:
Step 1. We select a time horizon.
This is a very important choice. Given that in the end we are all dead, the period over which we aim analyze the impact of digital privacy risks should not be too long. After all, we should be able to alter something in our situation on the basis of the analysis. On the other hand, if the period we select is too short, many real risks may have very small chance of occurring within that time interval. They will not show up at all on our radar screen, and we will ignore them to our peril.
Step 2. We estimate the likelihood and impact of all relevant negative outcomes that can happen within our time frame
Let us break this phrase down a bit:
- The Meaning of Relevant: Defines the scope of our analysis, the fact that we focus on the subset of uncertainties that concerns us, in this case digital privacy
- The Meaning of Negative Outcomes: means events (occurrences) with an identifiable impact on an objective metric that we care about.
- The Meaning of All: We make a complete little model of the future. This model is certainly not complete in reality (after all, we just focused already on relevant events) but it should be complete in the probability sense. For example, if we worry about event A or event B occurring separately, we should worry also about event A and event B occurring together.
The exercise of constructing a model of the future is much easier said than done. Countless people have had their entire careers working on recipes of how to do this for one risk phenomenon or another. People have even made a career bashing any standard recipes on how to construct such frameworks. Yet our opinion is that constructing such risk models is an indispensable analytical tool. Which brings us to the next question:
How do we estimate the likelihood and impact of privacy loss?
Privacy at Risk (PaR)
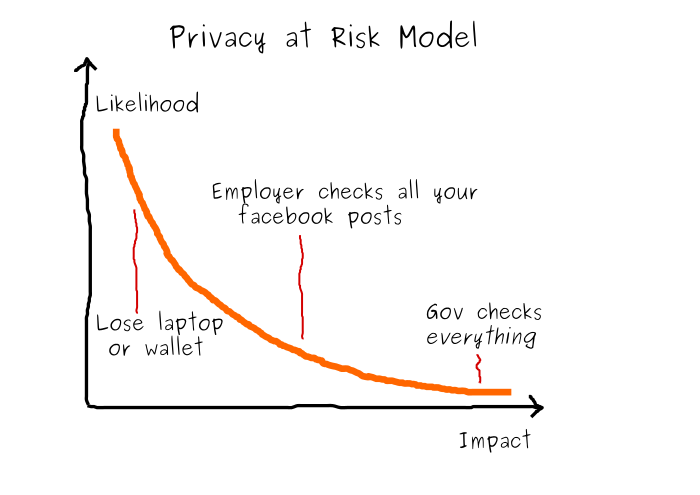
In building up our little model of privacy risks first we must select a time horizon and an associated context. Let us fix those as the possible impact of privacy events on our own life, career and societal path, over a period of five to ten years.
In mapping out the model it is useful to adopt a size based decomposition:
Small Scale (Idiosyncratic) Risks
How they happen: Our laptop is stolen (and it has some important private data). Or, we lose our wallet with identification documents. This can happen with a relatively high likelihood and at any time.
The impact: A snapshot of some of your private data leaks out. It is a sharp event, with important repercussions but it might be rather contained and non-recurring.
Medium Scale (Correlated) Risks
How they happen: Our entire behavioral dataset (what we say, like, buy etc.) is collected and distributed, legally or illegally by, for example, commercial interests. The likelihood of this type of data leak is lower (depending on jurisdiction and enforcement of laws), but it is still frequent enough.
The impact: Entire swathes of possible future actions and paths might be denied to us because other parties have access to (what they) consider actionable information. E.g., We might not get a job because of something we said online some years ago and have since long forgotten.
Large Scale (Tail) Risks
How they happen: Large aggregate datasets (what everybody says, likes, buys etc.) are collected and archived by e.g., government interests or others. While these are only used for well defined and approved purposes (depending on jurisdiction and enforcement) they may also get abused if the control environment changes. Checks and controls currently present in a democratic government may fall by the side as more authoritarian versions take control.
The impact: This type of event may lead to widespread oppression of arbitrary population segments (We cannot predict ex-ante who may be the victim). Such events are typical of small likelihood, but very large impact.
Putting it all together: Privacy at Risk distribution
What did this thought experiment teach us? Data privacy risks are not singular, isolated and black and white events. As the means and scale of data aggregation and dissemination intensify, so are the risks becoming more intertwined and large scale.
Failure in risk management is always a symptom of ignoring scenarios that are not too unlikely to be of interest. We tend to think that we can project into the future the certainties of today (for example that benign governments will never turning into abusing their citizens) but alas there are plenty of historical examples to the opposite. If we borrow the risk ranking language from the credit risk universe we can express this as follows:
Governments are not AAA rated in what concerns privacy risk, while Corporations are all over the place in the privacy rating spectrum, including junk rated
It is still early days for Privacy at Risk models
But it is definitely not early days for discussing the risks posed by data (non)privacy. Data privacy is one of the most impart risk issues going forward and we at Open Risk are not shying away!
Join the debate! Even better, start contributing to the Data Privacy Resources at the Open Risk Manual.