9 Ways Graphs Show Up in Data Science
We explore a variety of distinct uses of graph structures in data science. We review various important graph types and sketch their linkages and relationships. The review provides an operational guide towards a better overall understanding of those powerful tools
Course Objective
Graphs (and the related concept of Networks) have emerged from a relative mathematical and physics niches to become mainstream models for describing and interpreting various phenomena. The objective of the course is to review various important graph types as they are increasingly explored in data science and sketch their linkages and relationships (a graph of graphs!).
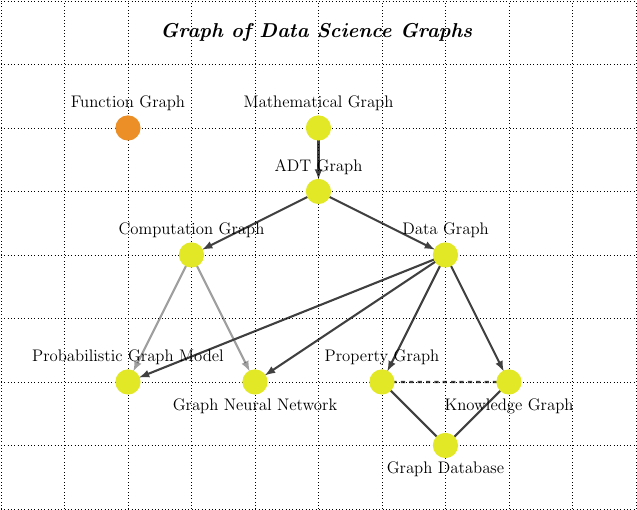
It is not meant to be a rigorous mathematical or computer science classification of graphs but rather an operational guide towards a better overall understanding of those powerful tools.
The course is now live at the Academy.
Pre-requisites
Basic knowledge of graph theory and some exposure to basic computer science concepts (such as data types) would be helpful.
Summary of the Course
What we cover in this course.
- Step 1. Introduction
- Step 2. The Graph of a Function
- Step 3. The Mathematical Graph
- Step 4. The Abstract Data Type (ADT) Graph
- Step 5. Computation Graphs
- Step 6. Data Graphs
- Step 7. Property Graphs
- Step 8. Knowledge Graphs
- Step 9. Graph Databases
- Step 10. Probabilistic Graph Models
- Step 11. Graph Neural Networks (GNN)
Get Started with the Course
The course is available at the Academy.